Natural Resource Biometrics1st order Spatial StatisticsHopkins' Index of aggregationHopkins' index of agregation is the ratio of the distance from a tree to it's nearest neighbor and the distance from random points within the same space to their nearest neighbor tree. where d(p-ti)i is the distance from a random point to it's nearest neighbor tree. d(t-ti)i is the distance from a tree to it's nearest neighbor tree. This test has a F distribution with F(2m,2m) (Hopkins, 1954). 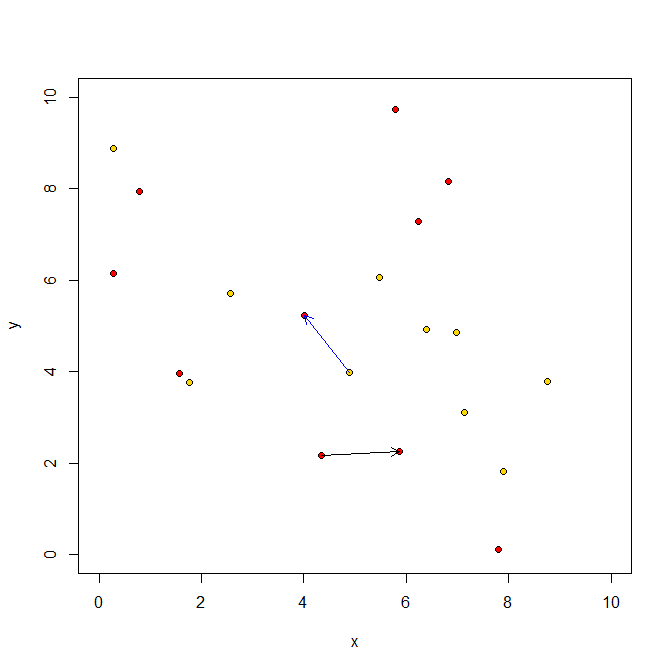
Figure 1. A example of how the Hopkin data is collected. The red dots are trees. The gold dots are random points. We collect the 1st nearest neighbor trees to the point distances and the tree to tree nearest neighbors. Byth and Ripley (1980) presented standardized index based on this test as: This index has a Normal null distribution N(1/2,1/12m).
Also See:
|

Natural Resources Biometrics by David R. Larsen is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License . Author: Dr. David R. Larsen Created: October 12, 2011 Last Updated: December 14, 2019 |